Scientific knowledge is produced piece meal through the slow process of research. One particular challenge in this process occurs when a researcher observes a difference between the experimental group and the control group. Did the difference arise because of chance or because of the experimental condition? Consider a child psychologist who is attempting to discern the most effective method for modifying explosive behaviors in children (say, ages 5 to 8). She designs a study in which the control group receives standard family counseling intervention while the treatment group receives standard family counseling plus Aikido martial arts training.

Suppose that the counseling + Aikido group exhibits a greater average reduction in explosive behaviors than the counseling alone group. What should the psychologist conclude? Was the difference really due to martial arts training? Or was there simply random variation between the two groups?
The observable world (a.k.a. the phenomenal or that which is accessible by our five senses) is characterized by variation. The world does have unifying undercurrents, however on the whole a vast multitude of divergent atomic structures abounds. In short, all things are not the same. There are alkali metals, alkaline earth metals, inert transition metals, transition metals and post-transition metals. There are tall people, short people, fat people, skinny people, brown skinned people, olive skinned people, red haired, brown eyed, toothy and toothless. Botanically, there are at least 40 different types of daffodils; each type of daffodil itself has a wide range of variable characteristics. This variation is what statisticians refer to when they use the terms "random error" or "random variation." On the other hand, variation due to some factor (e.g.: medication, exercise, psychotherapy, air pollution, etc) is referred to as explained variation. For example, consider an experiment which showed that lower carbon pollution levels curiously cause increased average temperatures in a simulated atmosphere.

Researchers want to know if this temperature variation is explained by reduced carbon pollution or by error (random variation). A high degree of variation in temperature recordings collected during the experiment may indicate that the average increase in temperature was a chance finding. In other words, if the variation in temperatures is great, then it may be that the researcher simply collected data during a time when temperatures were varying on the high end of the thermometer. Below I will show how the statisticians would answer the question, "Is the temperature rise due to the decreased carbon pollution or due to chance variation?"
When analyzing data sets from an experiment/study, researchers want to know if the observed change is a chance finding or a true reflection of how things really are. To do this they use a statistic called standard error (a quotient of standard deviation divided by the square root of the study sample size) to predict how variable the sample average would be if the experiment were repeated a large number of times. Essentially, the standard error statistic is used to calculate a range of values (termed "confidence interval") in which the researcher can be 95% confident that the true population average lies. Consider the atmospheric temperature study above. If the average temperature increased by 3.0 degrees Celsius, but the 95% confidence interval was -0.3 to 8.2 then it is entirely possible that no temperature change happened whatsoever (note that the value "0" is included in the range...indicating that the true average change in temperature may be 0 degrees Celsius). Such a scenario would indicate that the increase in temperature may truly be due to random variations or chance, not due to reduced carbon pollution.

Further testing can be done viz a viz Fisher's all powerful p-value to determine how insignificant the temperature rise truly is. In fact, selecting levels of significance and calculation of p-values will be the topic of next post. From there I will switch out of statistics mode and into philosophy mode.


![YBAR = SUM[Y(i)/N] where the summation is for 1 to N](http://itl.nist.gov/div898/handbook/eda/section3/eqns/mean.gif) .
.![s = SQRT[SUM(Y(i) - YBAR)**2/(N-1)] where the summation is from 1 to N](http://itl.nist.gov/div898/handbook/eda/section3/eqns/sd.gif) .
.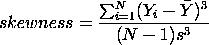 When this number is significantly positive then the data is not normally shaped and is lopsided to the right; when this number is negative then the data is lopsided to the left. Kurtosis is obtained similarly to skewness only the numerator is taken to the 4th power and standard deviation in the denominator is taken to the 4th power
When this number is significantly positive then the data is not normally shaped and is lopsided to the right; when this number is negative then the data is lopsided to the left. Kurtosis is obtained similarly to skewness only the numerator is taken to the 4th power and standard deviation in the denominator is taken to the 4th power 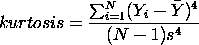 . A significantly negative kurtosis number indicates a flat curve and a positive kurtosis number indicates a tall, lanky curve.
. A significantly negative kurtosis number indicates a flat curve and a positive kurtosis number indicates a tall, lanky curve.